Haskell is a great language, but debugging Haskell is undoubtedly a weak spot. To help with that problem, I've just released the debug library. This library is intended to be simple and easy to use for a common class of debugging tasks, without solving everything. As an example, let's take a function we are interested in debugging, e.g.:
module QuickSort(quicksort) where
import Data.List
quicksort :: Ord a => [a] -> [a]
quicksort [] = []
quicksort (x:xs) = quicksort lt ++ [x] ++ quicksort gt
where (lt, gt) = partition (<= x) xs
Turn on the TemplateHaskell and ViewPatterns extensions, import Debug, indent your code and place it under a call to debug, e.g.:
{-# LANGUAGE TemplateHaskell, ViewPatterns #-}
module QuickSort(quicksort) where
import Data.List
import Debug
debug [d|
quicksort :: Ord a => [a] -> [a]
quicksort [] = []
quicksort (x:xs) = quicksort lt ++ [x] ++ quicksort gt
where (lt, gt) = partition (<= x) xs
|]
We can now run our debugger with:
$ ghci QuickSort.hs
GHCi, version 8.2.1: http://www.haskell.org/ghc/ :? for help
[1 of 1] Compiling QuickSort ( QuickSort.hs, interpreted )
Ok, 1 module loaded.
*QuickSort> quicksort "haskell"
"aehklls"
*QuickSort> debugView
The call to debugView starts a web browser to view the recorded information, looking something like:
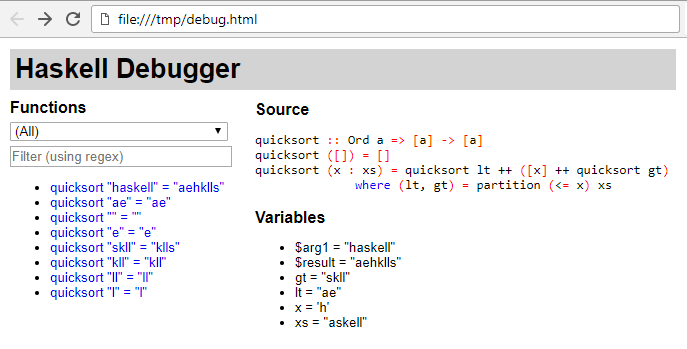
From there you can click around to explore the computation.
I'm interested in experiences using debug, and also have a lot of ideas for how to improve it, so feedback or offers of help most welcome at the bug tracker.
If you're interested in alternative debuggers for Haskell, you should check out the GHCi debugger or Hood/Hoed.
In Japanese: https://haskell.e-bigmoon.com/posts/2018-02-26-announcing-the-debug-package, by hgoetaroubig.
